
Today’s language models are mind-blowingly sensible…for generalists. Ask them about history, science, or current events; they’ll dazzle you with many facts and insights. But in the case of specialized, area of interest topics. That’s where even the mightiest AI brain can get a bit of fuzzy.
Imagine you’re a physician attempting to get help researching a rare medical condition. Or a lawyer searching for judgments on an obscure legal issue. Typical language models need more deep domain knowledge. It’s like asking a straight-A student to weigh in on quantum physics – they’re sensible, just not that sensible.
A team of researchers at UC Berkeley Propose Enter RAFT (Retrieval Augmented Fine Tuning), an ingenious latest approach that may very well be the Rosetta Stone for translating between generalized AI and hyper-specific expertise. It’s a method to stuff those highly capable but generalist language models stuffed with specialized knowledge and documentation. While tools like GPT-3 dazzle with broad capabilities, their performance gets shaky when domain-specific knowledge is required. Traditional methods like retrieval augmentation let models reference docs but don’t optimize for the goal domain. Supervised fine-tuning exposes them to domain data but lacks connection to retrievable evidence.
RAFT combines the perfect of each worlds through a novel training process mimicking an “open-book exam” setting:
1) It trains on question-answer pairs from the specialized domain.
2) But it also gets test-like prompts with a mixture of relevant “oracle” docs and irrelevant “distractor” docs.
3) Learning to sift through all that, cite pertinent quotes, and construct multi-step “chain-of-thought” reasoning.
Using distractors and sourced evidence, RAFT effectively cross-trains language models in domain comprehension and focusing skills.When evaluated on coding, biomedicine, and general question-answering benchmarks, RAFT demonstrated dramatic improvements over traditional fine-tuning approaches.
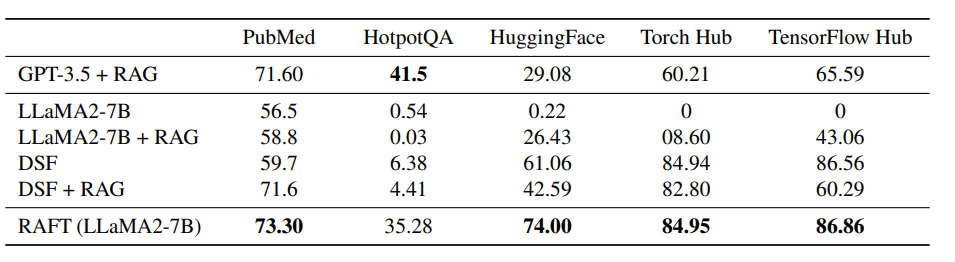
The evaluation results reveal RAFT’s clear superiority over existing baselines across a spread of specialised domains. When tested on datasets like PubMed biomedical literature, HotpotQA general questions, and coding benchmarks like HuggingFace and TorchHub, RAFT consistently outperformed standard language models and domain-specific fine-tuning methods. Compared to the bottom LLaMA2 model, RAFT exhibited dramatic gains, improving by a staggering 35.25% on HotpotQA and 76.35% on the TorchHub coding evaluation. It significantly outperformed domain-specific fine-tuning approaches as well, boosting performance by 30.87% on HotpotQA and 31.41% on the HuggingFace datasets over those methods. Even against the powerful GPT-3.5, RAFT demonstrated a transparent advantage when it got here to leveraging provided context and domain knowledge to resolve specialized questions accurately. The results highlight RAFT’s effectiveness in imbuing language models with proper material comprehension across technical domains.
More than simply incremental progress, RAFT represents a paradigm shift in unlocking domain mastery for language AI. We’re talking digital assistants and chatbots that may expertly guide you thru all the things from genetics to gourmet cooking.
While today’s language models are powerful generalists, RAFT offers a path toward true AI specialization and material expertise. Combined with their existing general reasoning, this might open up unprecedented latest frontiers across industries like healthcare, law, science, and software development.
By bridging the strengths of general reasoning and targeted expertise, RAFT clears a path toward a future where language AI transcends being “jacks of all trades” to grow to be true material authorities. It’s a pivotal step in creating artificial intelligence that matches or surpasses human mastery across every conceivable knowledge domain.
Check out the Paper and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
Don’t Forget to hitch our 38k+ ML SubReddit
This article was originally published at www.marktechpost.com




{kind=link}