
Apple hasn’t officially released an AI model yet, but a brand new research paper provides insight into the corporate’s progress in developing models with cutting-edge multimodal capabilities.
The papertitled “MM1: Methods, Analysis & Insights from Multimodal LLM Pre-training” introduces Apple’s MLLM family called MM1.
MM1 demonstrates impressive capabilities in image captioning, visual query answering (VQA), and natural language reasoning. The researchers explain that by fastidiously choosing image-caption pairs, they were capable of achieve excellent results, especially in low-shot learning scenarios.
What sets MM1 aside from other MLLMs is its superior ability to follow instructions across multiple images and reason concerning the complex scenes it presents.
The MM1 models contain as much as 30B parameters, which is 3 times as many as GPT-4V, the component that provides OpenAI’s GPT-4 its vision capabilities.
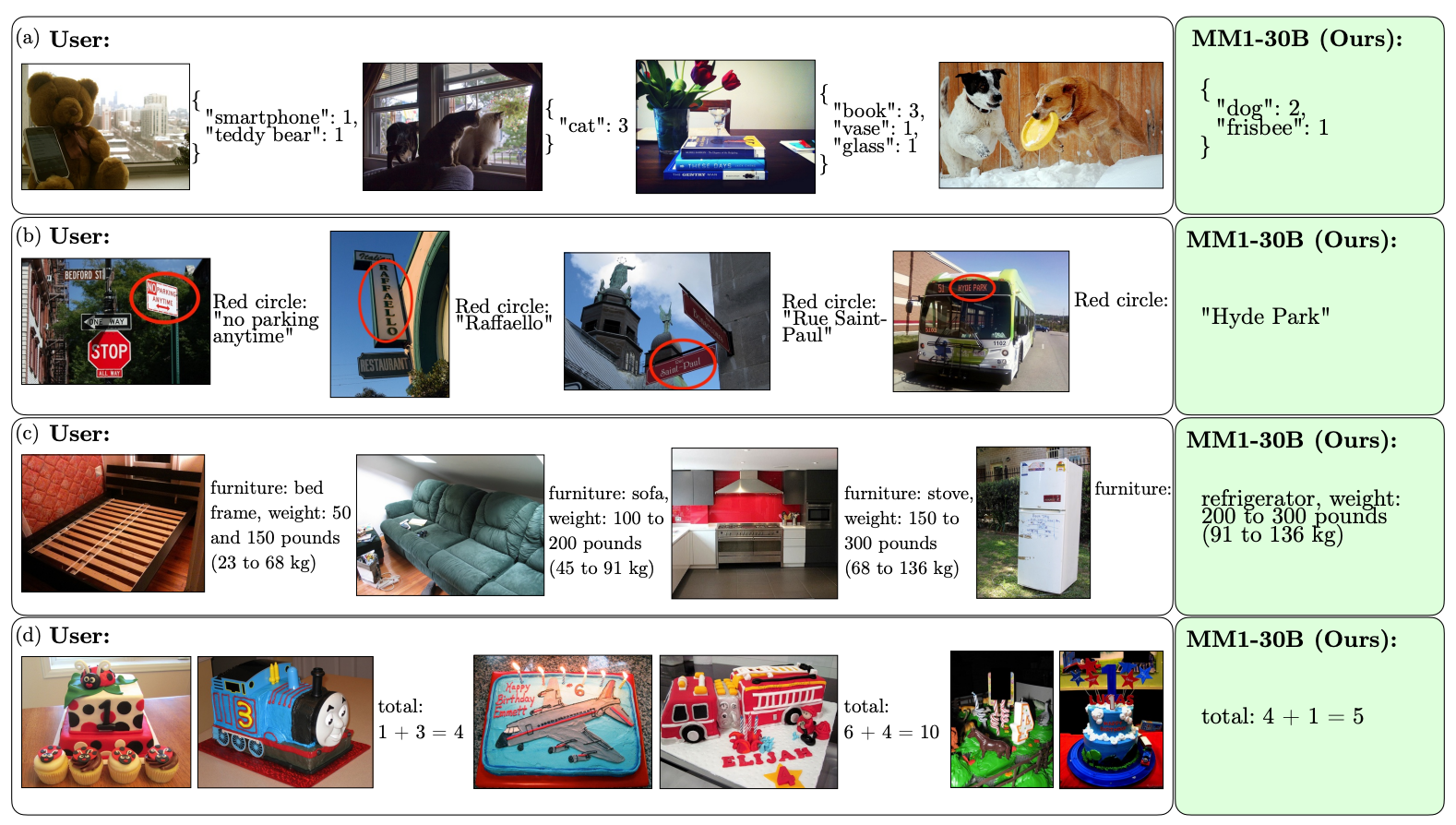
Here are some examples of MM1’s VQA capabilities.
MM1 underwent extensive multimodal pre-training with “a dataset of 500 million nested image-text documents containing 1 billion images and 500 billion text tokens.”
The scope and number of its pre-training allows MM1 to make impressive contextual predictions and track custom formatting with a small variety of few-shot examples. Here are examples of how MM1 learns the specified output and format using just 3 examples.
Creating AI models that may “see” and reason requires a vision-language connector that translates images and language right into a unified representation that the model can use for further processing.
The researchers found that the design of the video-to-voice port had less of an impact on MM1’s performance. Interestingly, image resolution and the variety of image tokens had the best impact.
It’s interesting to see how openly Apple is sharing its research with the broader AI community. The researchers explain: “In this paper, we document the MLLM construction process and try to articulate design lessons that we hope will probably be useful to the community.”
The published results will likely influence the direction other MMLM developers take by way of architecture and data selection before training.
How exactly MM1 models will probably be implemented in Apple’s products stays to be seen. The published examples of MM1’s abilities suggest that Siri will turn out to be much smarter when she eventually learns to see.
This article was originally published at dailyai.com



{kind=link}