
Despite the rapid advances in LLMs, our understanding of how these models handle longer inputs stays inadequate.
Mosh Levy, Alon Jacoby and Yoav Goldberg from Bar-Ilan University and the Allen Institute for AI examined how the performance of enormous language models (LLMs) changes with changes within the length of the input text they’re given to process.
They developed an argumentation framework specifically for this purpose, which allowed them to investigate the influence of input length on the LLM argument in a controlled environment.
The survey framework suggested different versions of the identical query, each containing the data mandatory to reply the query and padded with additional, irrelevant text of various lengths and kinds.
This allows the input length to be isolated as a variable and ensures that changes in model performance may be directly attributed to the length of the input.
Key findings
Levy, Jacoby, and Goldberg found that LLMs exhibit a major decline in reasoning performance at input lengths far below what the developers claim they will handle. They documented their findings on this study.
A decline was consistently observed across all versions of the dataset, indicating a systemic issue with processing longer inputs reasonably than a difficulty related to specific data samples or model architectures.
As the researchers describe: “Our results show a major degradation within the reasoning performance of LLMs at much shorter input lengths than their technical maximum. We show that the degradation trend occurs in every version of our data set, albeit with different intensity.”
Additionally, the study shows that traditional metrics reminiscent of perplexity, commonly used to judge LLMs, don’t correlate with the models’ performance on long-input reasoning tasks.
Further investigation revealed that performance degradation not only will depend on the presence of irrelevant information (padding), but can also be observed when this padding consists of duplicated relevant information.
If we keep the 2 core areas together and add text around them, the accuracy already drops. When paragraphs are inserted between sections, the outcomes drop much more. The drop occurs each when the texts we add are just like the duty texts and once they are completely different. 3/7 pic.twitter.com/c91l9uzyme
– Mosh Levy (@mosh_levy) February 26, 2024
This suggests that the challenge for LLMs is to filter out noise and the inherent processing of longer text sequences.
Ignore instructions
A critical area of failure mode highlighted within the study is the tendency of LLMs to disregard instructions embedded within the input because the input length increases.
Models also sometimes produced responses that suggested uncertainty or a scarcity of sufficient information, reminiscent of “The text doesn’t contain enough information,” regardless that all of the mandatory information was present.
Overall, as input length increases, LLMs appear to repeatedly struggle to prioritize and deal with essential information, including direct instructions.
Show prejudices within the answers
Another notable problem was the increasing biases within the models’ responses because the inputs became longer.
In particular, LLMs tended to reply “false” because the input length increased. This bias indicates a skew within the probability estimation or decision-making processes throughout the model, perhaps as a defense mechanism in response to increased uncertainty because of longer input lengths.
The tendency to prefer “fallacious” answers could also reflect an underlying imbalance within the training data or an artifact of the models’ training process, where negative answers could also be over-represented or related to contexts of uncertainty and ambiguity.
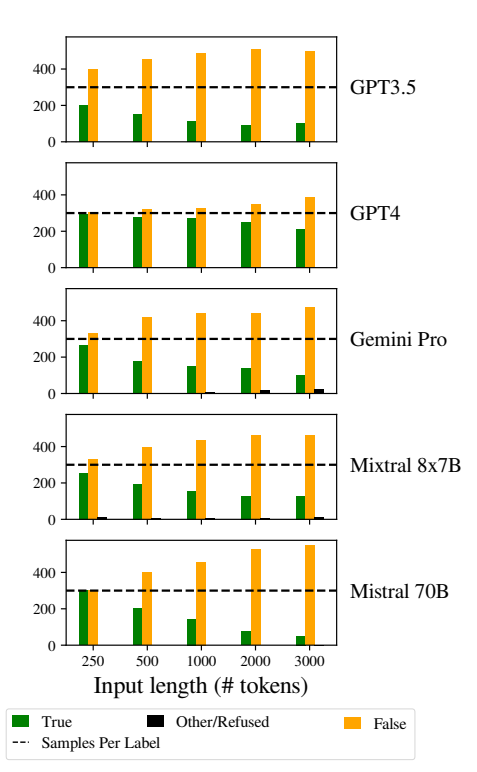
This tendency affects the accuracy of model results and raises concerns in regards to the reliability and fairness of LLMs in applications that require nuanced understanding and impartiality.
Implementing robust bias detection and mitigation strategies through the model training and tuning phases is critical to reducing unwarranted biases in model responses.
EEnsuring that training data sets are diverse, balanced, and representative of quite a lot of scenarios may also help minimize bias and improve model generalization.
This contributes to this other recent studies which also highlight fundamental problems with the way in which LLMs work, meaning that this “technical debt” could compromise the functionality and integrity of the model over time.
This article was originally published at dailyai.com




{kind=link}